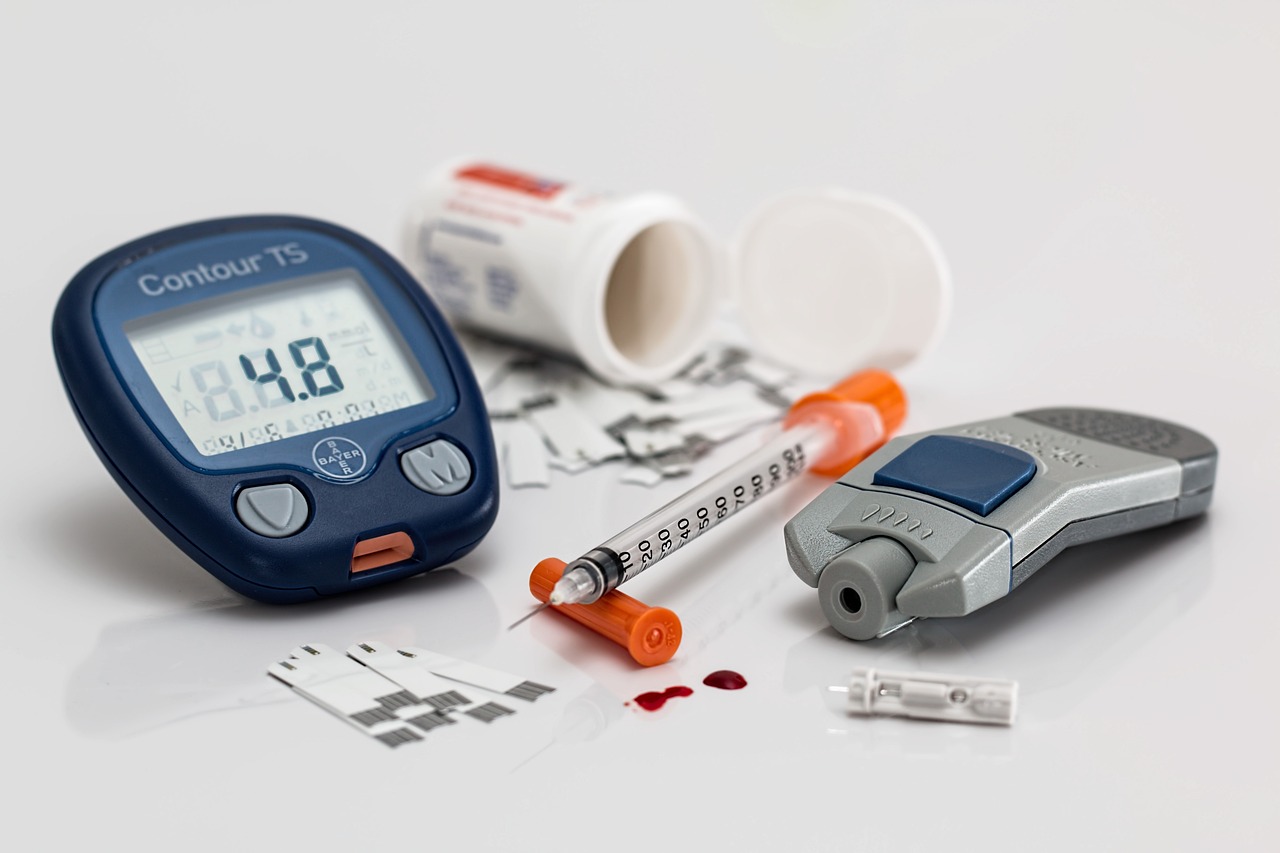
Un muy recomendable artículo en Nature, «A DIY ‘bionic pancreas’ is changing diabetes care — what’s next?», narra la evolución del cuidado de la diabetes de tipo 1 a medida que las metodologías empleadas para la medición de los niveles de azúcar en sangre y la administración de insulina han ido convirtiéndose en susceptibles de ser progresivamente más automatizadas.
El paso de dispositivos intrusivos, que requerían un pinchazo para llevar a cabo una medida puntual de la concentración de azúcar en sangre, a monitores constantes en forma de wearables; y la llegada de las bombas de insulina que automatizan su administración han mejorado sensiblemente la calidad de vida de los pacientes, pero requerían aún que esos pacientes estuviesen pendientes de sus lecturas para tomar decisiones en función de los parámetros ofrecidos. En muchos sentidos, es lo que el artículo describe como «tener que estar pensando constantemente en la diabetes para poder sobrevivir»: tener que estar leyendo los datos de sus monitores para pronosticar su dieta y su ejercicio, y calcular la dosis de insulina adecuada en cada momento.
A partir de ahí, un grupo de pacientes con conocimientos de tecnología se dedicaron a desarrollar software que les permitiese automatizar esas decisiones. La situación estaba ahí, la evolución de la tecnología les había brindado los dispositivos necesarios… quedaba automatizarlos, y las compañías dedicadas a ello no les daban solución al problema. Así que, en 2013, se organizaron en torno a un hashtag, #WeAreNotWaiting, y en 2015 presentaron un algoritmo en código abierto para la administración automatizada de insulina, en el que se han basado posteriormente varias compañías para proponer sus soluciones comerciales. El sistema requiere un miniordenador, que puede ser desde una Raspberry Pi hasta un smartphone, y es utilizado por un número relativamente bajo de pacientes, pero es el origen de muchos otros sistemas actuales, y tenía una característica fundamental: estaba desarrollado por personas que sabían lo que necesitaban.
Existen muchos otros sistemas que están en esa situación. Con una criticidad mucho menor y en absoluto comparable, por ejemplo, es lo que nos ocurre a quienes tenemos hogares completamente eléctricos equipados con dispositivos como placas solares, baterías, vehículos eléctricos y sistemas de aerotermia: cada componente te ofrece sus parámetros de funcionamiento mediante una app, pero si quieres mantener tu casa en modo óptimo, tienes que estar cada cierto tiempo mirando esas apps para asegurarte de que, por ejemplo, el coche no se ponga a cargar al tiempo que estás calentando o enfriando la casa y tienes el horno encendido. Algo completamente optimizable mediante software, que es evidente que será automatizado más pronto que tarde, y para lo que ni siquiera hace falta que utilicemos algoritmia muy inteligente: un conjunto de condicionales bien afinados podrían servir.


Sin embargo, estamos en lo de siempre: crear los condicionales necesarios para que un algoritmo pueda seleccionar las fotografías de tu dispositivo que contienen perros sería una tarea titánica y prácticamente imposible, porque hay perros de todos los tipos, hay imágenes de perros, hay perros fotografiados desde ángulos inverosímiles, etc. En su lugar, la solución propuesta por el machine learning es clara: alimenta un algoritmo con un montón de imágenes entre las que hay muchas etiquetadas como «perro», y deja que el algoritmo aprenda lo que es y no es un perro. Ese algoritmo, que desde hace tiempo podemos poner a prueba en cualquier smartphone, no requiere que un desarrollador se torture a sí mismo durante muchísimo tiempo pensando en todo tipo de condicionales infalibles, y funciona mucho mejor y con menos errores.
Así, si alimentamos un algoritmo con los datos que ofrecen las apps que utilizamos para controlar un hogar de estas características, el algoritmo podría, en no mucho tiempo, entender el propósito de los cambios que lleva a cabo el usuario y automatizarlos de manera óptima, liberando al inquilino de la necesidad de «estar todo el tiempo pensando en su consumo de electricidad». ¿Por que no se hace? Simplemente, porque aún es algo que necesitan relativamente pocas personas, y porque requiere trabajar con datos de muy diversos orígenes, muchos de ellos de apps que no ofrecen APIs, etc.
Me consta que hay compañías como Huawei que trabajan en esa dirección, algoritmos inteligentes que optimizan el consumo de una casa, pero aún no los he visto ofrecidos a los usuarios de manera generalizada. Probablemente, tan solo cuestión de tiempo.
A partir de aquí, lo que tenemos que pensar es cuántas cosas responden a ese tipo de automatización inteligente, porque las compañías que sepan entenderlo y ofrecerlo a sus usuarios o introducirlos en sus procesos ganarán lógicamente mucho en términos de atractivo para sus mercados o de eficiencia en sus procesos. Para un directivo que conozca bien sus operaciones, este tipo de razonamientos no requiere tanto: es más «entender lo que se puede pedir y cómo pedirlo» que plantearse un proyecto de software complejísimo con el que pocos se encuentran a gusto. Es, simplemente, adquirir un poco de cultura básica sobre cómo funcionan estas cosas. O como en el caso de los diabéticos, simplemente entender lo que necesitas.